












Ever feel trapped in a digital labyrinth of PDFs? Text you desperately need seems locked away in an uneditable format, forcing you to spend hours retyping information or struggling with clunky copy-and-paste workarounds. Scanned documents add another layer of frustration, their text hidden behind a barrier of images. Wouldn't it be amazing to effortlessly unlock the valuable content within any PDF, scanned or editable, and transform it into usable text for your projects and workflows? Imagine boosting your productivity, streamlining tasks, and saying goodbye to manual retyping drudgery. This guide is your key to escaping the PDF text trap! With the help of PDF Agile, you'll discover how to extract text from any PDF with ease and accuracy, saving you time and frustration. Get ready to unleash the hidden potential within your digital documents!
How to Extract Text from a PDF (Scanned or Editable) with PDF Agile?
For complex scanned PDFs or situations where accuracy is paramount, PDF Agile desktop software offers a robust solution with advanced OCR capabilities:
Extract text from a scanned PDF with PDF Agile
Step 1: Download and Install PDF Agile
Head over to the official PDF Agile website and download the software compatible with your operating system (Windows or Mac). Once downloaded, follow the on-screen instructions to install PDF Agile on your computer.
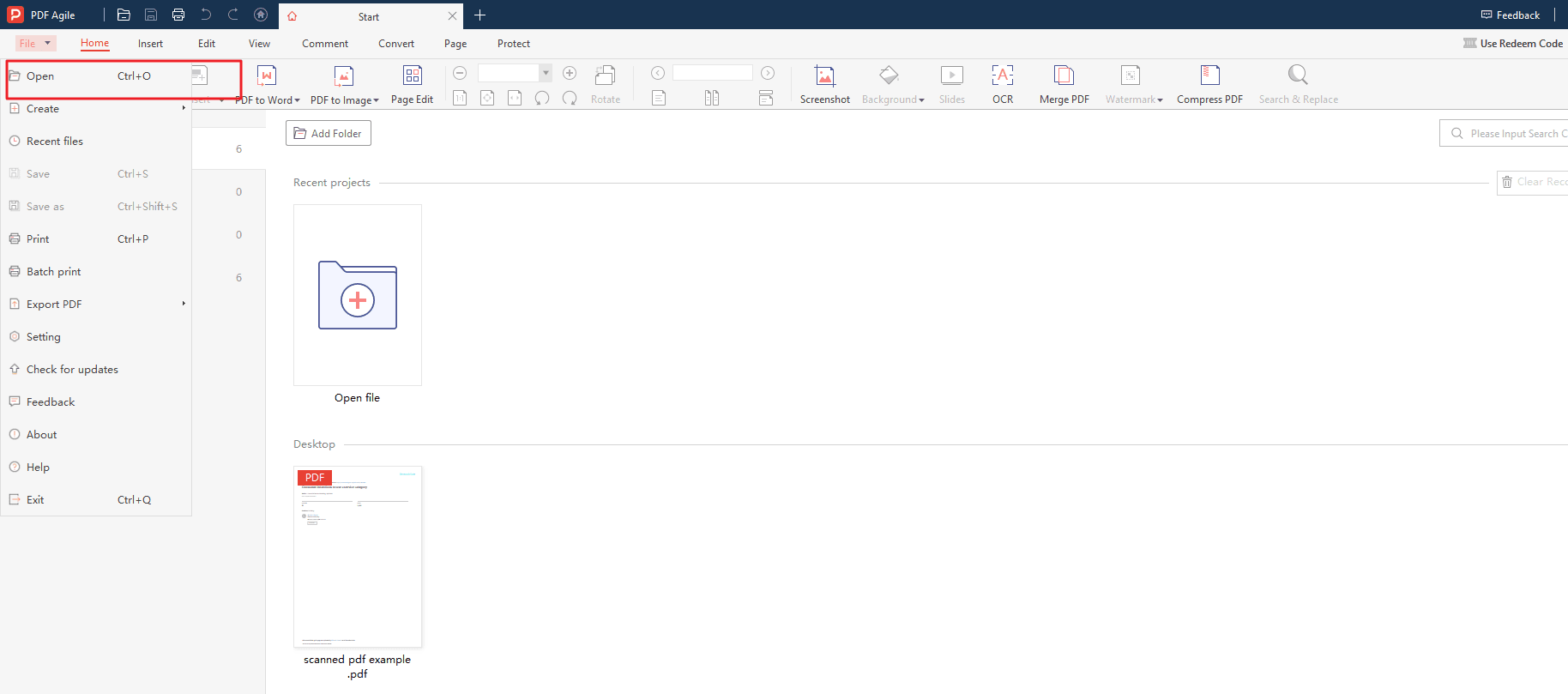
Step 2: Open Your Scanned PDF
Firstly, launch PDF Agile and locate the "File" menu at the top of the interface, then click "Open" and navigate to the location of your scanned PDF on your computer. Thereafter, double-click the file to open it within the PDF Agile program.
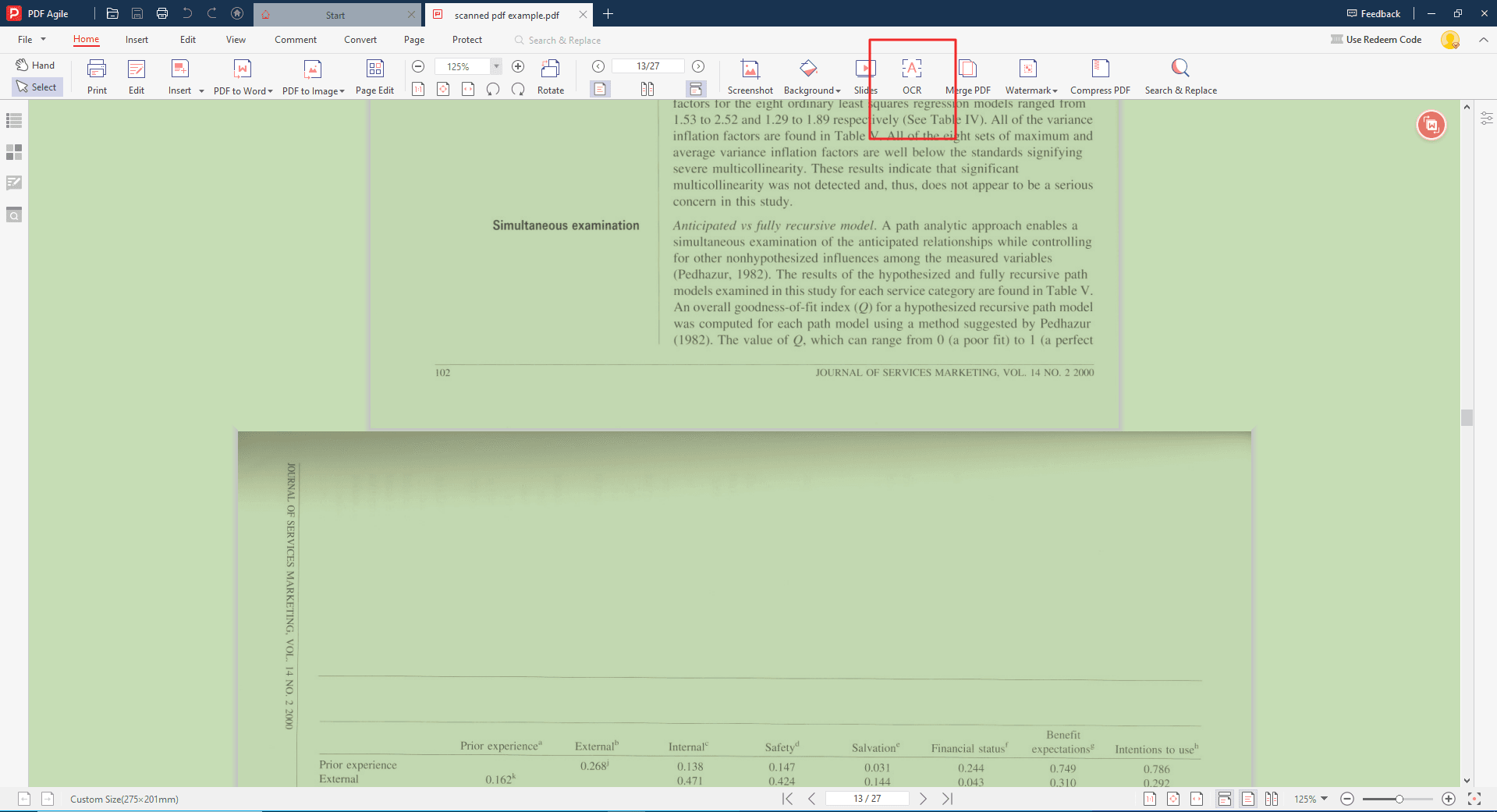
Step 3: Initiating OCR Conversion directly
Here comes to the first approach. With your scanned PDF open, locate the "OCR" section within the PDF Agile interface. Then, click on the "OCR" button. This will initiate the OCR process, where PDF Agile analyzes the scanned images and converts the embedded text into editable characters.
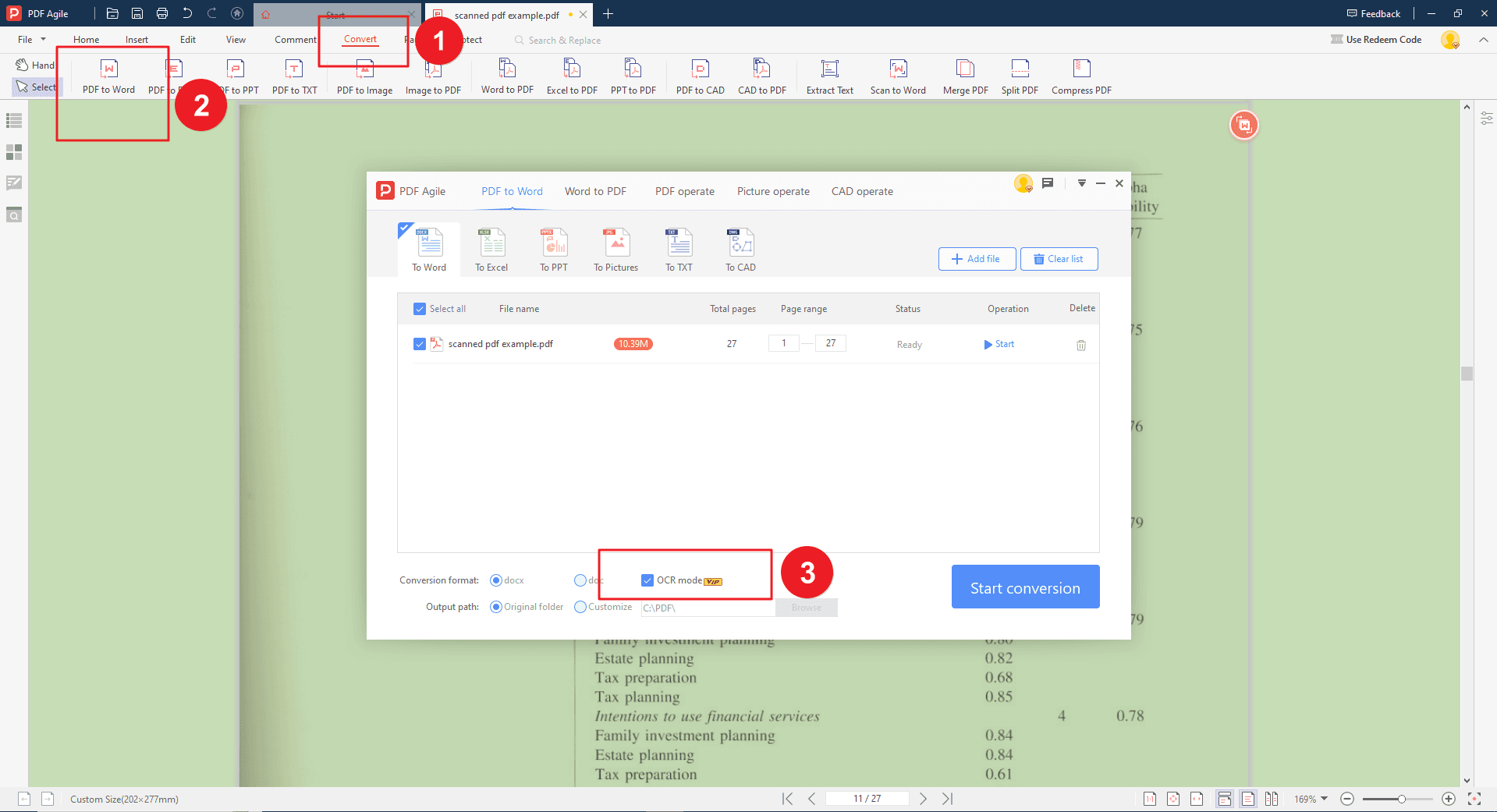
Step 4: Applying PDF-to-Word through OCR Conversion (Alternatively)
Here comes to the second approach. With your scanned PDF open, locate the "Convert" section within the PDF Agile interface. Then, click on the "PDF to Word" button. There will be various conversion formats, which are docx, doc, and OCR model. After selecting the OCR model, PDF Agile analyzes the scanned images and converts the embedded text into editable characters.
Step 5: Performing Conversion and Accessing Document
Once you've reviewed and adjusted the OCR settings according to your needs, click on the "Start" or "Start Conversion" button within the OCR menu. PDF Agile will perform the conversion process. The processing time might vary depending on the size and complexity of your scanned document, but the software offers progress indicators to keep you informed. Upon successful conversion, PDF Agile will display the newly editable document within the program window. You'll now see the extracted text as editable characters within the document. This allows you to edit the text directly, copy and paste it, or save it in a different format.
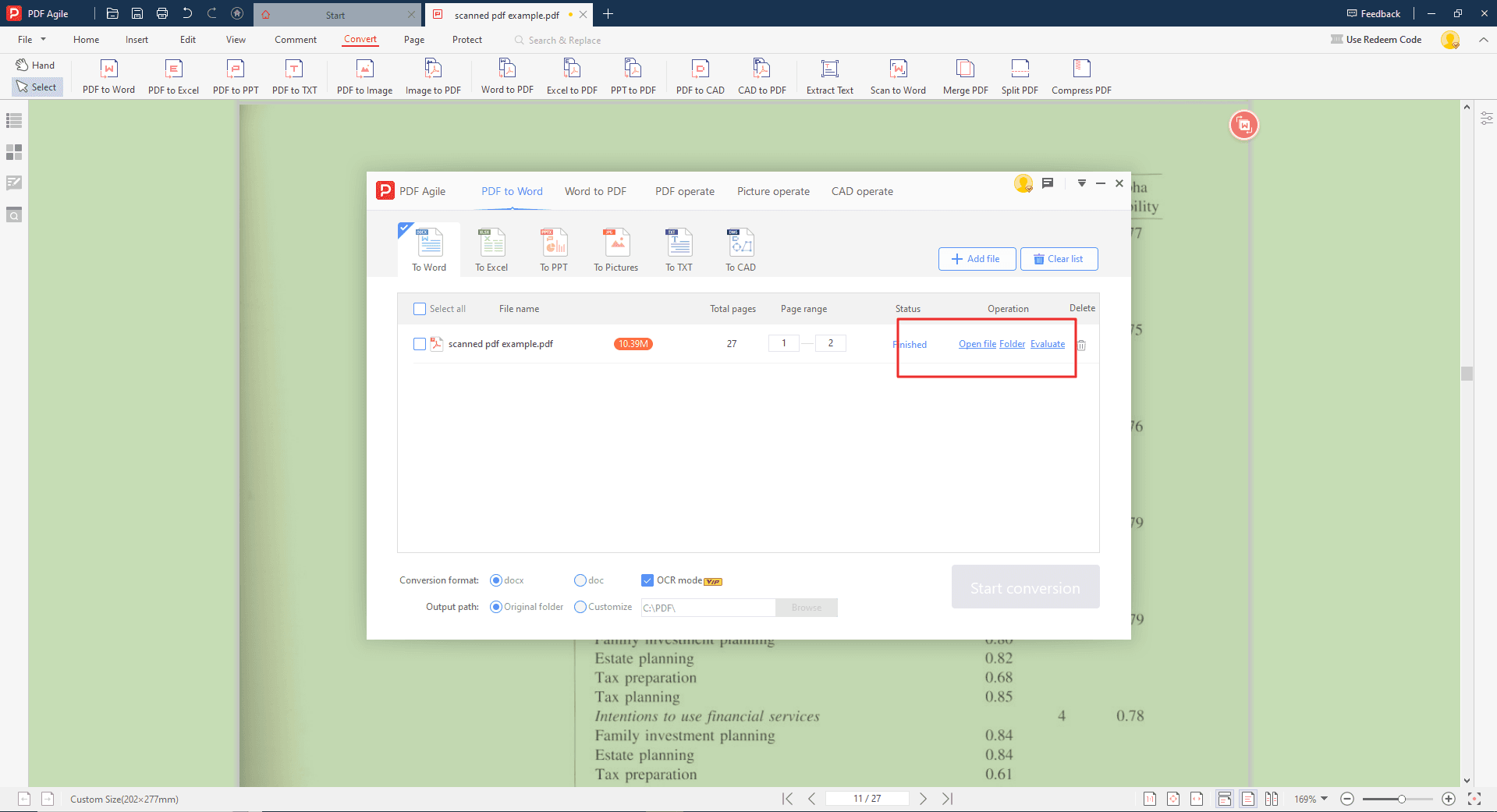
Extract text from an editable PDF with PDF Agile
With the editable PDF open, you can directly highlight and copy the text you want to extract. Right-click on the selected text and choose "Copy" from the menu. The copied text can then be pasted into a text editor, word processor, or another program.

How to Extract Text from a Scanned PDF with Adobe Acrobat?
Here's a detailed step-by-step guide on extracting text from a scanned PDF with Adobe Acrobat, incorporating insights from the official website description:
Extract Text from a Scanned PDF with Adobe Acrobat
Step 1: Open the Scanned PDF
Launch Adobe Acrobat on your computer. And go to the "File" menu and select "Open", browse your files and choose the scanned PDF document you want to extract text from.
Step 2: Initiating Scan & OCR
This is the first path. Click the arrow on the right side of the Acrobat interface to expand the tools menu. From there, select "Scan & OCR". Here, you can customize the OCR settings if needed (though automatic settings usually work well). You can adjust the language of the scanned text and select specific page ranges for OCR if you only need text from a portion of the document. Click "OK" to confirm the settings and start the OCR process.

Step 3: Using PDF Editing to initiate OCR (Alternatively)
This is the other path. Click on the "Tools" section in the right pane of the Acrobat interface. Then, locate the "Edit PDF" tool and click on it. If OCR starts automatically, you'll see a progress bar or message indicating the process. In this case, proceed to step 3. If OCR doesn't initiate, click on the "Recognize Text" icon within the "Edit PDF" section. This will launch the OCR tool.
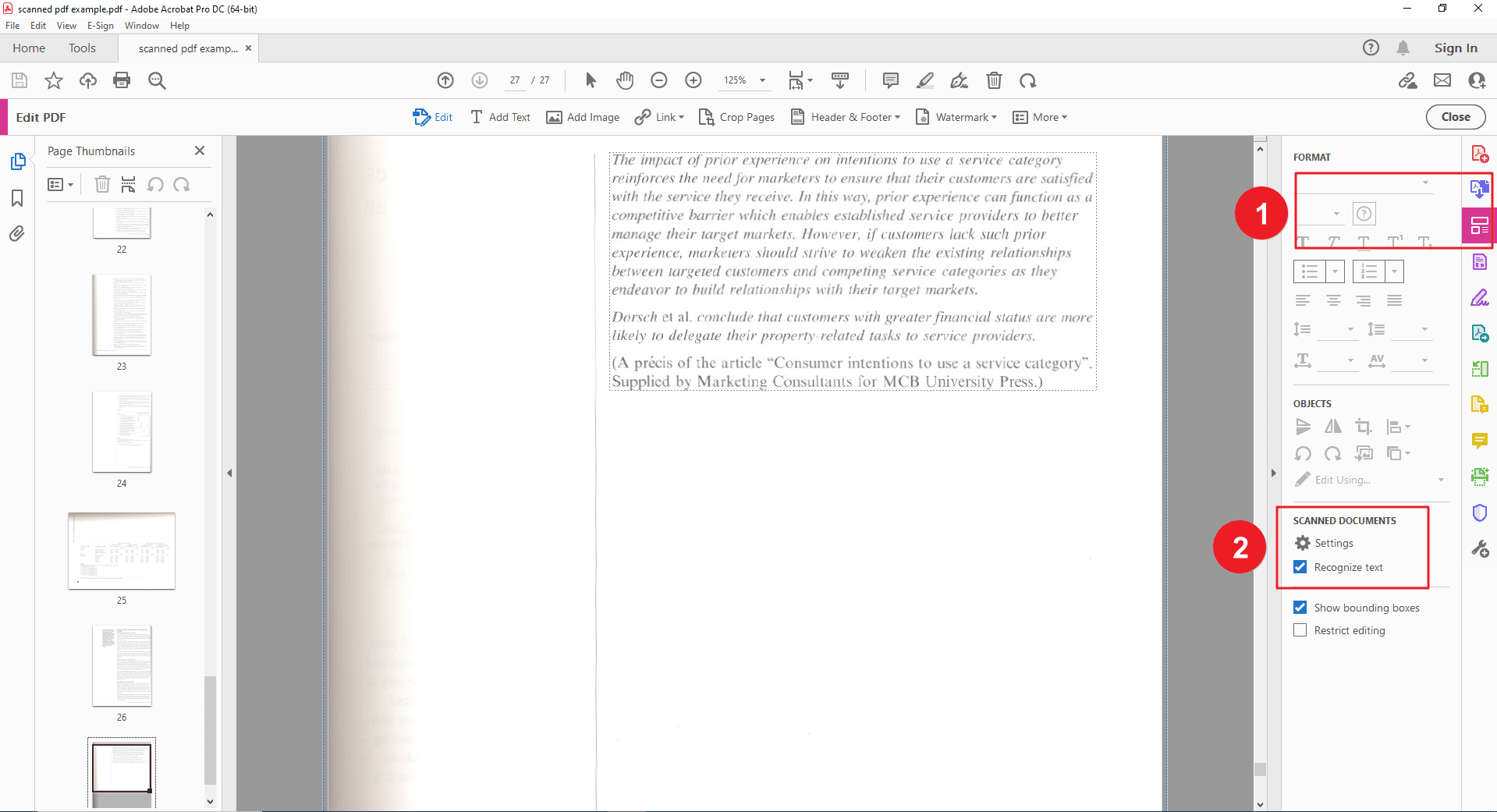
Step 4: Extract Text from OCR PDF
You can directly highlight and copy the text you want to extract. Right-click on the selected text and choose "Copy" from the menu. The copied text can then be pasted into a text editor, word processor, or another program.
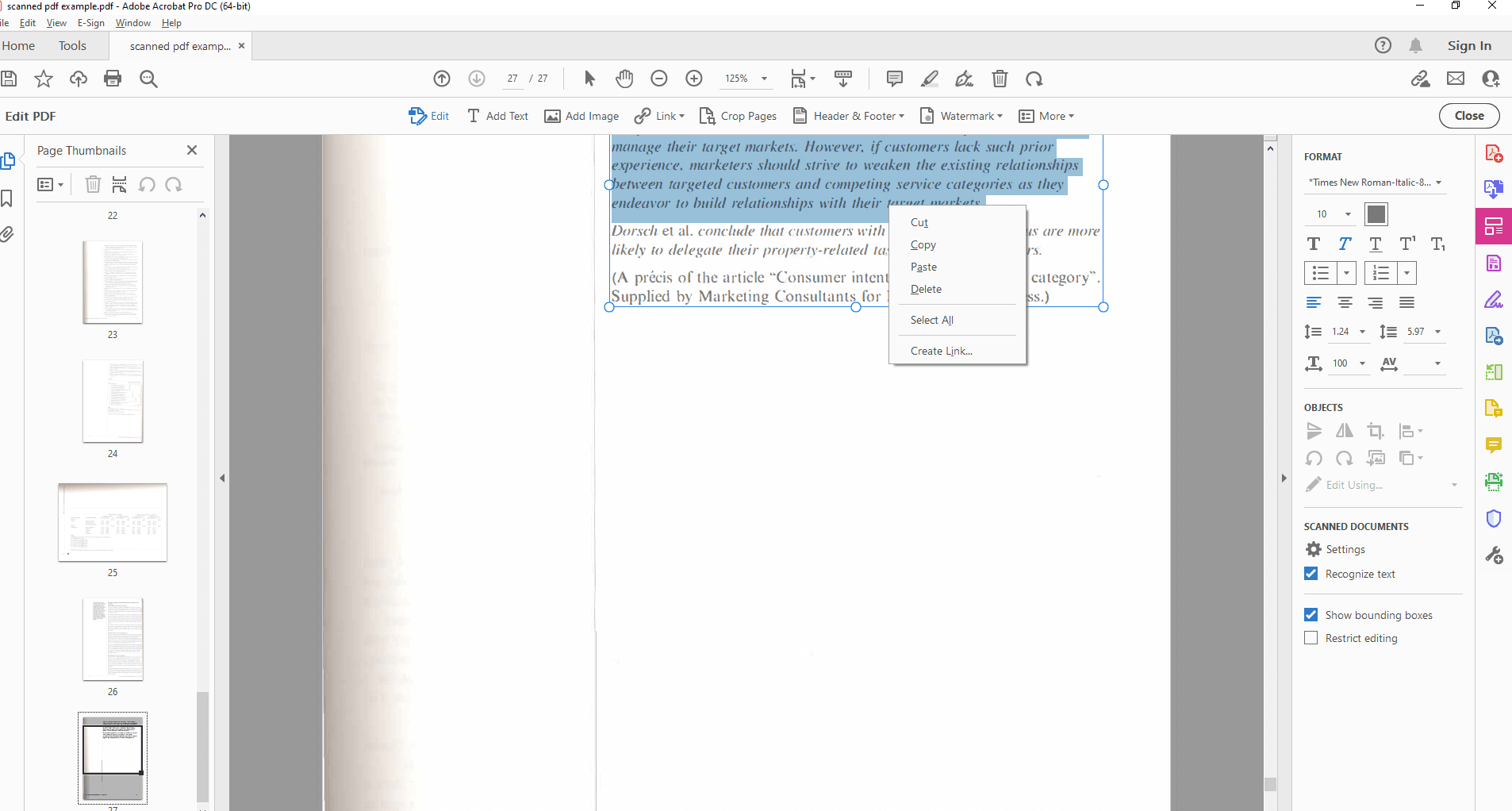
Extract Text from an editable PDF with Adobe Acrobat
Navigate to the desired section of the PDF where you want to extract text. Use your cursor to highlight the text you want to copy. Right-click on the highlighted text and select "Copy" (or use the keyboard shortcut Ctrl+C on Windows or Cmd+C on Mac). Open another application where you want to paste the extracted text (e.g., Word document, notepad).
Advantage of PDF Agile
Effortless Extraction: Go beyond the limitations of basic copy-paste with a suite of tools designed for seamless text retrieval. No more tedious retyping or struggling with clunky interfaces.
Advanced OCR Magic: For scanned PDFs, PDF Agile utilizes cutting-edge OCR (Optical Character Recognition) technology to transform scanned images into editable text with remarkable accuracy. Wave goodbye to blurry characters and hello to crystal-clear, usable text.
More Than Just Extraction: PDF Agile doesn't stop at just extracting text. It empowers you to manipulate and edit the extracted content, maximizing its value and integrating it seamlessly into your workflow.
Flexibility for All Needs: Whether you need a quick online solution for simple text grabs or require the advanced control and accuracy of desktop software for complex documents, PDF Agile offers a perfect solution.
With PDF Agile, you can:
Extract text from any PDF, scanned or editable.
Experience unmatched accuracy thanks to advanced OCR technology.
Edit and manipulate the extracted text for maximum usability.
Choose between online convenience or desktop software power for ultimate flexibility.
FAQs
Are there limitations to online OCR converters?
File size restrictions: Some converters limit the size of PDFs they can handle. Large or complex scanned documents might not be supported.
Security concerns: Uploading sensitive documents to online services might raise security concerns for some users.
Limited features: Online converters typically focus on basic conversion and might lack advanced features like page range selection or output format choices.
Are there alternative methods for text extraction?
For basic needs, some operating systems such as translation software or reading software offer text-grabbing tools that can extract limited text from PDFs. However, these tools lack the accuracy, efficiency and control offered by dedicated OCR software like PDF Agile.
When should I consider using PDF Agile desktop software?
Accuracy is crucial: Advanced OCR settings and superior technology provide optimal accuracy for challenging documents.
You need control: You can define page ranges, output formats, and adjust settings for a customized extraction process.
Security is a concern: Working offline with sensitive documents on your local machine offers greater security compared to online converters.
Advanced editing is required: PDF Agile allows editing the extracted text directly within the document, a feature not available with most online converters.



